![]()
![]()
![]()
2 Preliminaries
2.1 Graphs: Notation and Definitions
A graph ![]() consists
of a set of vertices
consists
of a set of vertices ![]() and
a collection of edges
and
a collection of edges ![]() .
. ![]() is not necessarily a set.
The order of a graph is the number of its vertices,
is not necessarily a set.
The order of a graph is the number of its vertices, ![]() , and the size of a graph is the
number of its edges,
, and the size of a graph is the
number of its edges, ![]() . We will assume that the
order and size of a graph are finite.
. We will assume that the
order and size of a graph are finite.
![]() is called an undirected graph if
is called an undirected graph if ![]() consists of unordered pairs
of vertices,
consists of unordered pairs
of vertices, ![]() ,
, ![]() .
. ![]() is called a directed
graph or digraph if
is called a directed
graph or digraph if ![]() consists of ordered pairs of vertices,
consists of ordered pairs of vertices, ![]() ,
, ![]() . If
. If
![]() ,
, ![]() ,
, ![]() is called a symmetric
graph and is equivalent to an undirected graph.
is called a symmetric
graph and is equivalent to an undirected graph.
The underlying graph of a given
directed graph is created by replacing every directed edge ![]() with its corresponding undirected edge
with its corresponding undirected edge
![]() . Mixed graphs contain both
directed and undirected edges.
. Mixed graphs contain both
directed and undirected edges.
![]() is
called a subgraph of
is
called a subgraph of ![]() if
if ![]() and
and ![]() .
. ![]() is said to be induced by the set of
vertices
is said to be induced by the set of
vertices ![]() if
if ![]() . In other words, if
. In other words, if ![]() includes all edges of
includes all edges of ![]() that join two vertices in
that join two vertices in ![]() . If
. If ![]() is a subgraph of
is a subgraph of ![]() ,
, ![]() is called a supergraph of
is called a supergraph of ![]() .
.
The vertices and edges in a graph may be associated with information, called labels. In a social network graph where vertices correspond to people and edges correspond to relationships among people, vertex labels could contain first and last names and birthdays. Edge labels could contain details of the relationships. A graph is called edge-weighted if edge labels contain an edge’s length or weight. In a vertex-weighted graph, vertex labels contain a weight.
Two or more edges that are represented by
the same pair of vertices are called parallel edges. An edge ![]() or
or ![]() is
called a loop. An undirected graph without parallel edges and loops is
called a simple graph.
is
called a loop. An undirected graph without parallel edges and loops is
called a simple graph.
Parallel edges and loops often have a special meaning. In many applications, they represent redundant or contradictory information and are thus not allowed. In a social network graph, for instance, it may not be desired that a person can have a relationship with himself. On the other hand, a network that models different types of relationships (e.g., work relationship, friendship) may allow parallel edges.
We use ![]() to
denote the neighborhood of an arbitrary vertex
to
denote the neighborhood of an arbitrary vertex ![]() . For directed graphs,
. For directed graphs, ![]() .
For undirected graphs,
.
For undirected graphs, ![]() . Every vertex in
. Every vertex in ![]() is called adjacent to
is called adjacent to ![]() . For directed graphs, we
additionally define
. For directed graphs, we
additionally define ![]() . We use
. We use ![]() and
and ![]() to
denote the degree and indegree of
to
denote the degree and indegree of ![]() .
.
A walk between two vertices ![]() and
and ![]() is an alternating sequence of vertices and
edges
is an alternating sequence of vertices and
edges ![]() where, for directed graphs,
where, for directed graphs, ![]() ,
, ![]() ,
and for undirected graphs,
,
and for undirected graphs, ![]() ,
, ![]() .
.
The length of a walk is the number
of edges in the walk. In edge-weighted graphs, the sum of the weight of all
edges in the walk is typically counted as its length. ![]() is
called the source of the walk,
is
called the source of the walk, ![]() is
called its destination. All remaining vertices in the walk are called intermediary
vertices.
is
called its destination. All remaining vertices in the walk are called intermediary
vertices.
A trail is a walk in which all edges
are distinct. A path is a walk in which all vertices are distinct. Every
path is a trail. A closed walk is a walk in which the source is also the
destination. A circuit is a closed walk in which no edges repeat. A cycle
is a circuit in which no vertices repeat. For instance, ![]() is
a circuit but not a cycle.
is
a circuit but not a cycle. ![]() is neither a
circuit nor a cycle. A graph with no cycles is called an acyclic graph
or a forest.
is neither a
circuit nor a cycle. A graph with no cycles is called an acyclic graph
or a forest.
Let ![]() and
and ![]() be two arbitrary vertices.
be two arbitrary vertices. ![]() is said to be reachable from
is said to be reachable from ![]() if there exists a path from
if there exists a path from ![]() to
to ![]() .
. ![]() and
and ![]() are said to be connected if either
are said to be connected if either ![]() is reachable from
is reachable from ![]() , or
, or ![]() is reachable from
is reachable from ![]() . A graph is called connected if every pair of
vertices is connected. A connected graph with no cycles is called a tree.
A connected component
. A graph is called connected if every pair of
vertices is connected. A connected graph with no cycles is called a tree.
A connected component ![]() of
of ![]() is a connected induced subgraph of
is a connected induced subgraph of ![]() such that no edge in
such that no edge in ![]() contains a vertex from
contains a vertex from ![]() and a vertex from
and a vertex from ![]() . The transitive closure
. The transitive closure
![]() of
of ![]() is a supergraph of
is a supergraph of ![]() that contains edge
that contains edge ![]() if
if
![]() is reachable from
is reachable from ![]() .
.
A complete graph ![]() is a simple graph with
is a simple graph with ![]() vertices in which every vertex is
adjacent to every other vertex. A bipartite graph is a graph whose
vertices can be divided into two disjoint sets such that no vertex is adjacent
to a vertex in the same set. An extensive survey of graph classes can be found
in [4].
vertices in which every vertex is
adjacent to every other vertex. A bipartite graph is a graph whose
vertices can be divided into two disjoint sets such that no vertex is adjacent
to a vertex in the same set. An extensive survey of graph classes can be found
in [4].
The density of a graph describes its size-to-order ratio. The terms dense and sparse are typically used to compare the density of multiple graphs or graph classes. A complete graph, for instance, is a maximally dense simple graph.
One of the most well-known problems in graph theory is the shortest path problem. Its objective is to find a path of minimal length between two given vertices. The problem is relevant to many practical applications, including automated navigation, network planning, and very-large-scale integration (VLSI) design.
A common generalization of the shortest
path problem is the single-source shortest path problem. Its objective
is to find all shortest paths from a given vertex to all other vertices in the
graph. The shortest path tree for an arbitrary source vertex ![]() is an acyclic subgraph
is an acyclic subgraph ![]() of
of ![]() where
where ![]() contains
contains ![]() and all vertices reachable from
and all vertices reachable from ![]() , and
, and ![]() contains all edges in a shortest path for
each vertex in
contains all edges in a shortest path for
each vertex in ![]() .
.
2.2 Memory Hierarchy
A computer system contains several components for storing data. These components differ in terms of cost, capacity, and performance and serve different purposes in the system. The memory hierarchy is a scheme that orders the components from smallest, fastest, and closest to the central processing unit (CPU) to largest, slowest, and furthest from the CPU. The classical depiction of the memory hierarchy is shown on the left of Figure 1. Data usually passes through the hierarchy level-by-level, as indicated by the arrows.

Cache is the fastest memory in a computer. Modern personal computers have between two and four megabytes (MB) of cache memory. Part of it is often built onto the same chip as the CPU. The processor can access cached data within a few nanoseconds.
Main memory stores data the computer actively operates on. Modern personal computers have between one and three gigabytes (GB) of main memory. The typical time to transfer data from main memory to cache is in the 10 to 100 nanosecond range. It is generally assumed that access time does not depend on the order in which data is retrieved.
Magnetic disk drives are today’s medium of choice for storing large amounts of data. Unlike cache and most types of main memory, disk drives are nonvolatile; that is, data is preserved when the power is switched off. Modern disk drives have a capacity of up to two terabytes (TB), and a personal computer can have several disk drives built in. The time to retrieve a byte stored on a disk drive is approximately 10 milliseconds. Finding the real time is more complex because disk drives are mechanical devices. The next section looks in detail at the properties of disk drives.
Tertiary storage comprises very large external storage systems, such as tape libraries and optical jukeboxes. These systems are designed for data that is not frequently accessed, such as backups or archives. Access time is high, but cost per byte of storage is low.
2.3 Disk Drives
The main component of a disk drive is the platters that rotate around a central spindle (see Figure 1). The upper and lower surface of each platter is coated with a thin layer of magnetic material. One disk head per surface is responsible for sensing (reading) and recording (writing) bits of information in the magnetic flux that passes under it. The disk heads are mounted to an actuator arm that moves the heads across the surfaces. The disk heads are always positioned in parallel, and typically only one head can either read or write at any one time.
The right part of Figure 1 illustrates how data is organized on a surface. The concentric circles are called tracks. Small gaps divide each track into sectors. Each sector can hold a fixed amount of data, typically 512 bytes or 4 kilobytes (KB). A sector is the smallest addressable unit in a disk drive. Every read or write operation involves at least one sector. If part of a sector is corrupted, the entire sector cannot be used.
Modern disk drives use a technique called multiple zone recording to put more sectors on outer tracks than on inner tracks. Multiple zone recording increases both the capacity of the disk and the speed at which sectors in outer tracks can be accessed. A cylinder is a set of tracks from all surfaces that are at the same radius from the spindle.
A common diameter for platters is 3.5 inches (8.9 cm), and a common rotational speed is 120 rotations per second. A typical disk has between 6 and 12 surfaces, each with around 50,000 tracks, each with between 1000 and 2000 512-byte sectors.
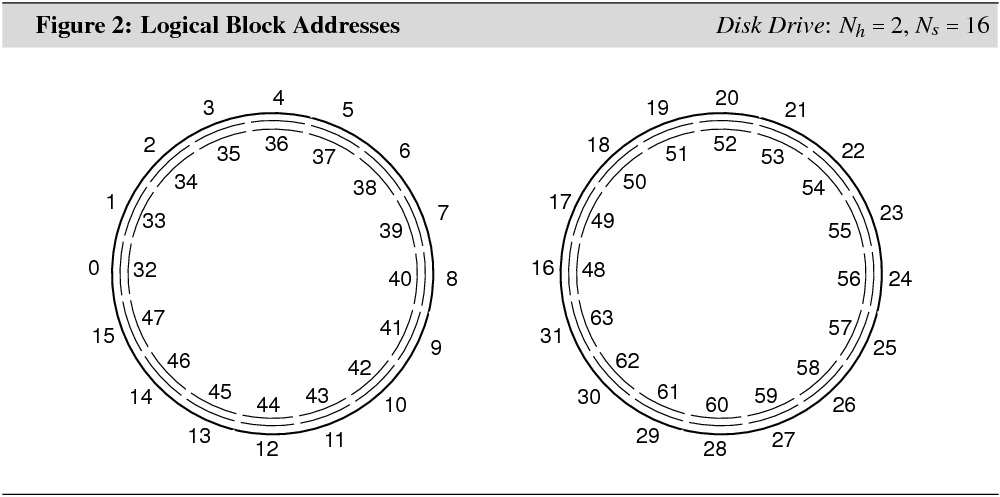
Each sector is uniquely identified by a 3-tuple of cylinder number, head number, and sector number (abbreviated CHS). Cylinder numbering starts at 0 for the outmost cylinder and increases inward. In a disk drive with 8 surfaces, disk heads are numbered from 0 to 7. Sectors are numbered per track, starting at 1. In early computer systems, sectors had to be addressed directly by their CHS tuples.
In modern computer systems, logical
block addresses (LBAs) have replaced CHS addresses. A LBA is a unique
integer for each sector. The sector with CHS tuple ![]() has
LBA 0. More generally, in the absence of multiple zone recording,
has
LBA 0. More generally, in the absence of multiple zone recording, ![]() , where
, where ![]() is
the number of disk heads, and
is
the number of disk heads, and ![]() is the number of
sectors per track. Figure 2 shows LBAs for the sectors in the first two
cylinders in a disk with
is the number of
sectors per track. Figure 2 shows LBAs for the sectors in the first two
cylinders in a disk with ![]() and
and ![]() .
.
File systems use LBAs to cluster sectors with adjacent addresses into blocks, and make a block their smallest addressable unit. The size of a block is chosen when the file system is initialized. Typical block sizes are 4 KB and 8 KB. Choosing a larger block size can reduce disk access time, choosing a smaller block size reduces internal fragmentation. Two blocks are called adjacent if the sector with the highest LBA in one block is adjacent to the sector with the lowest LBA in the other block.
The delay between the time when data stored on the disk is requested and the time when it arrives via the bus at its destination (e.g., main memory) can be broken down into data access time and data transfer time. Data access time can be further broken down into seek time, rotational latency, and head switch time. The former two factors dominate:
• Seek time is the delay for positioning the disk heads over the cylinder that holds the first sector of the requested data. A seek is composed of four phases [21]: A speedup phase, where the actuator arm is accelerated; a coast phase, where the arm moves at maximum velocity; a slowdown phase, where the arm is brought close to the desired track; and a settle phase, where the head is adjusted to the desired location. Seeks of only a few cylinders are dominated by the settle phase, seeks of a few hundreds cylinders are dominated by the speedup phase, long seeks spend most time moving at constant speed. Only for long seeks is seek time roughly proportional to seek distance.
Moving the heads across the entire disk takes about 10 milliseconds in a typical disk drive.
• Rotational latency is the delay
between the time when the heads have been positioned over the correct cylinder
and the time when the first sector of the requested data passes by. Rotational
latency is inversely proportional to the rotational speed of the disk. On
average, rotational latency is half of the time needed for a full rotation. For
instance, the average rotational latency in a disk with a rotational speed of
120 rotations per second is ![]() milliseconds.
milliseconds.
• Head switch time is the delay for activating the correct disk head. A head switch is an electronic process and typically takes less than a millisecond.
Data transfer time is the remaining delay after the correct head has been activated and positioned over the first sector of the requested data. Data transfer time depends mainly on the rotational speed of the disk. Additional factors are the number of gaps that have to be passed, and the number of head switches and track switches that take place. A head switch takes place when the requested data is stored in two or more tracks in the same cylinder. A track switch takes place when it is stored in two or more adjacent cylinders. In order for either switch to take place without much rotational latency, sectors on different surfaces are typically laid out with small offsets to each other.
The disk drive places incoming read or write requests in a request queue. The order in which requests are then serviced depends on the disk’s scheduling algorithm. A common algorithm is the elevator algorithm. This algorithm services a new request that arrives while the disk drive is still working on an old request if the new request is in the current direction of the arm movement.
Disk drives can typically send and receive data faster over the bus than they can read it from or write it on the disk. To hide this difference, disk drives have cache memory that acts as a speed-matching buffer.
Many disk drives use this memory also to perform read-ahead. Read-ahead is an optimization where the disk drive continues to read data into the cache after a read request has been serviced. If the next request is for the cached data, it can be sent over the bus instantly. Read-ahead is usually only performed when the request queue is empty.
Even if a disk does not implement read-ahead, some sectors before or after the first sector of the requested data may be available in the disk’s cache. These sectors are collected after the correct disk head has been activated and positioned over the correct track, while the drive waits for the first sector of the requested data to pass by.