![]()
![]()
![]()
7 Accessing G-Store
G-Store and its query engine are accessed through queries. Queries can be submitted through a command-line interface (see Figure 10) or through a text file. A query in a text file can be called from the command-line interface or from a command-line argument (g-store.exe filename).
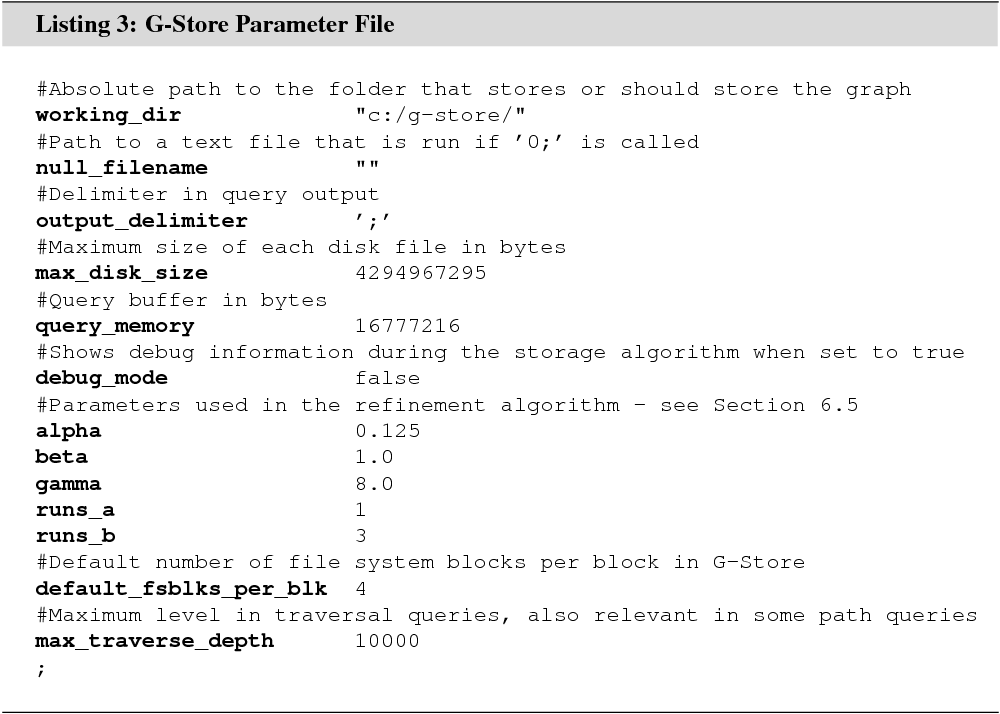
Parameters can be submitted into G-Store’s algorithms through a parameter file. The file must be named _parameter.g and be placed in the same folder as the G-Store executable. Figure 3 shows the format of the file as well as the most important parameters and their default values.
G-Store simulates a disk drive through one or multiple files. File access is implemented through the Windows API to bypass any buffering mechanisms in the operating system. The maximum size of a file can be controlled with parameter max_disk_size. The files are placed in the folder specified in parameter working_dir.
When G-Store is started, a graph representation in working_dir is automatically loaded. Multiple graph representations must be stored in individual folders. To load a graph in a different folder, G-Store must be restarted.
If no graph representation is found in working_dir, the user can create one from an input graph. Before G-Store
creates a new representation, the user is asked if he wants to change the
default block size of default_fsblks_per_blk ![]() . If query performance is critical, a
user should experiment with different block sizes. The largest supported block
size is currently 65,536 bytes. The block size must be a positive multiple of
the hard disk’s sector size, but G-Store will recommend to choose a multiple of
the file system’s block size.
. If query performance is critical, a
user should experiment with different block sizes. The largest supported block
size is currently 65,536 bytes. The block size must be a positive multiple of
the hard disk’s sector size, but G-Store will recommend to choose a multiple of
the file system’s block size.
The remainder of this section introduces G-Store’s query language and important parts of G-Store’s query engine.
7.1 Menu


DESCRIBE prints information about the loaded graph and its representation on the disk. The print-out includes a list of the names, identifiers, and data types of vertex labels.
RUN "filename" executes a query in a text file. The file can contain either schema_def, query_def, or multiple query_def. Multiple query_def are executed in sequence and do not affect each other (i.e., the buffer is cleared after each query). It is not possible to submit multiple query_def through the command-line interface – the user has to wait for a query to return before he can submit a new query.
0 is a shortcut to the call RUN null_filename. null_filename can be set via the parameter file.
EXPORT TO exports the loaded graph to an SQL file that can be entered into a PostgreSQL or Oracle database. The algorithm converts G-Store’s data types to appropriate data types in the target database and replaces identifiers that are reserved. PSQLCOPY creates an export that can be entered into a PostgreSQL database via COPY. Caution: If an error occurs during COPY, PostgreSQL aborts the insertion. Already inserted tuples are left as dead data in the database. The user can run VACUUM to recover the dead space.
EXPORT TO needs the original text file that contains the input graph. If it has been moved since it was used to create the graph representation in G-Store, its new location has to be specified in FROM "filename".
HELP prints an overview of recognized commands in extended Backus-Naur form.
EXIT terminates G-Store.
7.2 Schema Definition
CREATE GRAPH creates a disk representation for an input graph. graph_name is an arbitrary character string that identifies the graph.
l_name is a unique character string that identifies a label. Each label is assigned a number, l_num, based on its position in the schema definition. The first label is assigned l_num 0. Both l_num and l_name can be used to select labels in queries.
The table below lists the available data types for vertex labels.
l_type Bytes per vertex Details----------------------------------------------------------------BOOL 1 INT(n) n Signed integer, n = {1, 2, 4, 8}UINT(n) n Unsigned integer, n = {1, 2, 4, 8}DOUBLE 8 CHAR(n) n n does not include '\0'VARCHAR length+2 length does not include '\0'SKIP 0 Label is not loaded into G-Store
IS ID tells G-Store to load the vertex identifiers in the input graph into the representation. The l_type preceding IS ID must be an integer type.
FROM "filename" specifies the path to the text file that defines the input graph. The expected format is illustrated below.
#comment|V| |E|0 label0 label1 ... edge0 edge1 ...1 label0 label1 ... edge0 edge1 ......|V|-1 label0 label1 ... edge0 edge1 ...
The file has ![]() lines
(excluding comment lines). The first line contains the order and size of the
graph, separated by a space. The remaining lines contain the vertex data.
Vertices are identified by integers in the range
lines
(excluding comment lines). The first line contains the order and size of the
graph, separated by a space. The remaining lines contain the vertex data.
Vertices are identified by integers in the range ![]() .
Vertices are listed in increasing order of their identifiers.
.
Vertices are listed in increasing order of their identifiers.
The first value in each line is the identifier. Then follow the values of vertex labels in the order in which the labels appear in the schema definition. A value for a BOOL label must begin with either T, t, 1, F, f, or 0. A value for a CHAR or VARCHAR label must be enclosed with quotation marks. Quotation marks and backslash characters within a CHAR or VARCHAR label must be escaped (\", \\). A NULL value is not currently supported in G-Store.
Finally follows a list of the identifiers of adjacent vertices. The list must not be ordered. G-Store ignores loops and repeated occurrences of the same edge with a warning message.
By default, G-Store’s storage multilevel algorithm is used to map the input graph to blocks. The disk representation can also be created differently:
BASED
ON "filename" uses an existing function ![]() stored in a text file to create the
representation. The file is expected to contain the partition number for vertex
stored in a text file to create the
representation. The file is expected to contain the partition number for vertex
![]() in line
in line ![]() . G-Store’s finalization algorithm
takes care of any partitions that are too large to fit in a block (see Section
6.6).
. G-Store’s finalization algorithm
takes care of any partitions that are too large to fit in a block (see Section
6.6).
FLAT creates the disk representation either by randomly mapping vertices to blocks (RANDOM) or by adopting the order in which vertices are listed in the input text file (STRAIGHT). In both cases, G-Store tries to place as many vertices in a block as possible.
7.3 Query Definition
A SELECT query extracts a table from a loaded graph. The rows are vertices, the columns are labels or pseudolabels. By default, the table is printed to the command line. SPOOL TO "filename" prints the table to a file. Printing to a file is usually much faster than printing to the command line.
By default, the rows contain all vertices of the loaded graph. Their order matches the order in which they are stored on the disk. A traverse_clause or path_clause puts the result of a graph traversal or path search algorithm in the rows. The WHERE clause filters the rows for vertices whose labels or pseudolabels satisfy cond.
The select_list sets the columns of the output table. The available labels and pseudolabels are listed below. AS l_alias changes the name of a label or pseudolabels that appears in the column header.
Label Description----------------------------------------------------------------* All labelsl_name Label name as set in the schema definitionl_num Label number based on position in schema definition Pseudolabel Description----------------------------------------------------------------GID G-Store's global vertex identifierCOUNT_EDGES DegreeISLEAF 1 if COUNT_EDGES = 0, 0 otherwiseROWNUM Starts at 1, incremented for each row returnedLEVEL Length of the path from the sourceISCYCLE In traversal queries: 1 when a cycle is closed, in path queries: 1 just before a cycle could be closed, 0 otherwiseLPAD A specific label, left-padded with a specific character by the length of the path from the source PATH A specific label from each vertex in the path, separated by a specific characterSOURCE A specific label from the source vertex
7.4 Conditions
expr must match the type of the label or pseudolabel before the inequality sign. A character string must be enclosed with quotation marks. A condition on a characters string is evaluated based on ASCII order. It is case sensitive.
logical_cond combines the results of two or more conditions to a single result. It can also invert the result of a condition. An example is given below.
l_name >= expr AND NOT (l_num > expr OR l_name = expr)
Parentheses and the following operators are supported: AND, OR, and NOT. The standard precedent order applies. Internally, G-Store creates a tree from a logical condition and evaluates it inorder. A subtree is not evaluated if the truth of the parent is already known. The figure below illustrates the tree for the logical condition above. l_name >= expr is evaluated first, then AND. If l_name >= expr evaluates to false, the right subtree of AND is not evaluated.
AND / \ l_name >= expr NOT \ OR / \ l_num > expr l_name = expr
While parsing the WHERE condition, G-Store extracts the highest possible values for ROWNUM and LEVEL. For instance, in
LEVEL < 20 AND ROWNUM < 100 OR l_name = expr AND ROWNUM < 40
the highest possible ROWNUM is 99 and the highest possible LEVEL is ![]() . The former is used to
terminate query evaluation when sufficiently many rows have been found, the
latter controls the depth during traversal.
. The former is used to
terminate query evaluation when sufficiently many rows have been found, the
latter controls the depth during traversal.
7.5 Graph Traversal
The traverse_clause implements depth-first traversal. The clause is conceptually similar to the CONNECT BY clause in Oracle and EnterpriseDB databases (see Section 4.2.4). The START WITH condition specifies the source vertices. ANY makes every vertex a source vertex. Vertices are put in the output rows in the order in which they are visited.
If NOCYCLE is set, G-Store cuts off a path as soon as a cycle is detected. Without NOCYCLE, G-Store ignores cycles.
A path is always cut off when its length reaches either the highest possible LEVEL in the WHERE condition (see previous section) or parameter max_traverse_depth. In the latter case, G-Store prints a warning message.
Together with pseudolabel PATH, a traverse_clause can extract all paths between two sets of vertices. The source set is specified in the START WITH condition, the destination set in the WHERE condition.
Listing 4 shows pseudocode for the algorithm and explains how buffer space is utilized. Buffering tries to exploit the fact that G-Store stores vertices close to vertices in their neighborhood.

7.6 Path Search
IN PATH returns one path between a vertex that matches the START WITH condition and a vertex that matches the END WITH condition. If a THROUGH condition is specified, every intermediary vertex in the path satisfies it. The query puts the vertices along the found path in the output rows. The length of the found path is printed to the command line.
IN PATH is particularly useful for testing if one group of vertices is reachable from another group of vertices. The length of the returned path is typically larger than the length of a shortest path, but the time to find the path can be much shorter.
IN PATH is realized implemented through block-first search, a novel traversal order that combines BFS and DFS. The main idea is to explore as many vertices as possible in the buffered pages before loading new pages into the buffer. Pseudocode is shown in Listing 5.
IN PATH may exhaust G-Store’s memory stack if parameter max_traverse_depth is set too high. Apart from the obvious solutions, decreasing max_traverse_depth and increasing the memory stack, decreasing query_memory can also prevent stack exhaustion.
IN SHORTEST PATH returns a shortest path between two sets of vertices, optionally by passing through specific vertices. START WITH, END WITH, and THROUGH as above. The query is realized through BFS. The implementation is complex and optimized – we refer the interested reader to query_spath.cpp.
IN SHORTEST PATH TREE finds a shortest path for each vertex that is reachable from any vertex that matches the START WITH condition, optionally by passing through specific vertices. Unlike the two previously presented queries, IN SHORTEST PATH TREE puts only the destination vertices in the output rows. The user can include pseudolabel PATH in select_list to get the actual shortest paths. The length of the longest shortest path is printed to the command line.
